
PostgreSQL Table Partitioning — Growing the Practice — Part 1 of 2



At Fountain, we’re fans of PostgreSQL, 🐘 especially the capabilities that help us meet the demands of high volume hiring.
Recently we faced a challenge working with a large table where query performance had worsened. This is a high growth database table that tracks applicants as they move through their hiring process.
Read on to find out how we solved it.
The Fountain Hire platform keeps detailed information here to help hiring managers stay in close communication with candidates. Job seekers are working often on short timelines, and their hiring process includes a lot of interaction with automated processes.
In this post, we’ll look at how PostgreSQL table partitioning helped us solve our operational challenges from rapid data growth.
Outline
- Why did we use table partitioning?
- How did we roll out this change?
- How did the process go?
- Table partitioning and Cost Savings
- Challenges and Mistakes
- Future Improvements
Why
Performance can degrade when working with high growth rate tables. Queries slow down. Modifications like adding indexes or constraints take longer.
One solution is to split up the table into a set of smaller tables. By moving away from a single large table, each smaller table becomes easier to work with.
From version 10 of PostgreSQL, splitting tables is possible with Declarative Partitioning. One of the benefits of Declarative Partitioning is that it is easier to introduce compared with how table partitioning was done in the past. In earlier versions of PostgreSQL table inheritance, trigger functions and check constraints were required.
Smaller tables are easier to work with, but there is still a question about when to perform a conversion. To answer that, let’s briefly discuss the architecture and memory for PostgreSQL, a single writer database. PostgreSQL has a fixed amount of memory available to the server. PostgreSQL recommends migrating a table to a partitioned table when the size of a table exceeds the amount of system memory.
Since our database server had 384GB of memory and since the table size was nearly 1.5 TB, we felt that it was a good time to perform the conversion. This conversion would help our maintainability and scalability as the table continued to grow in size.
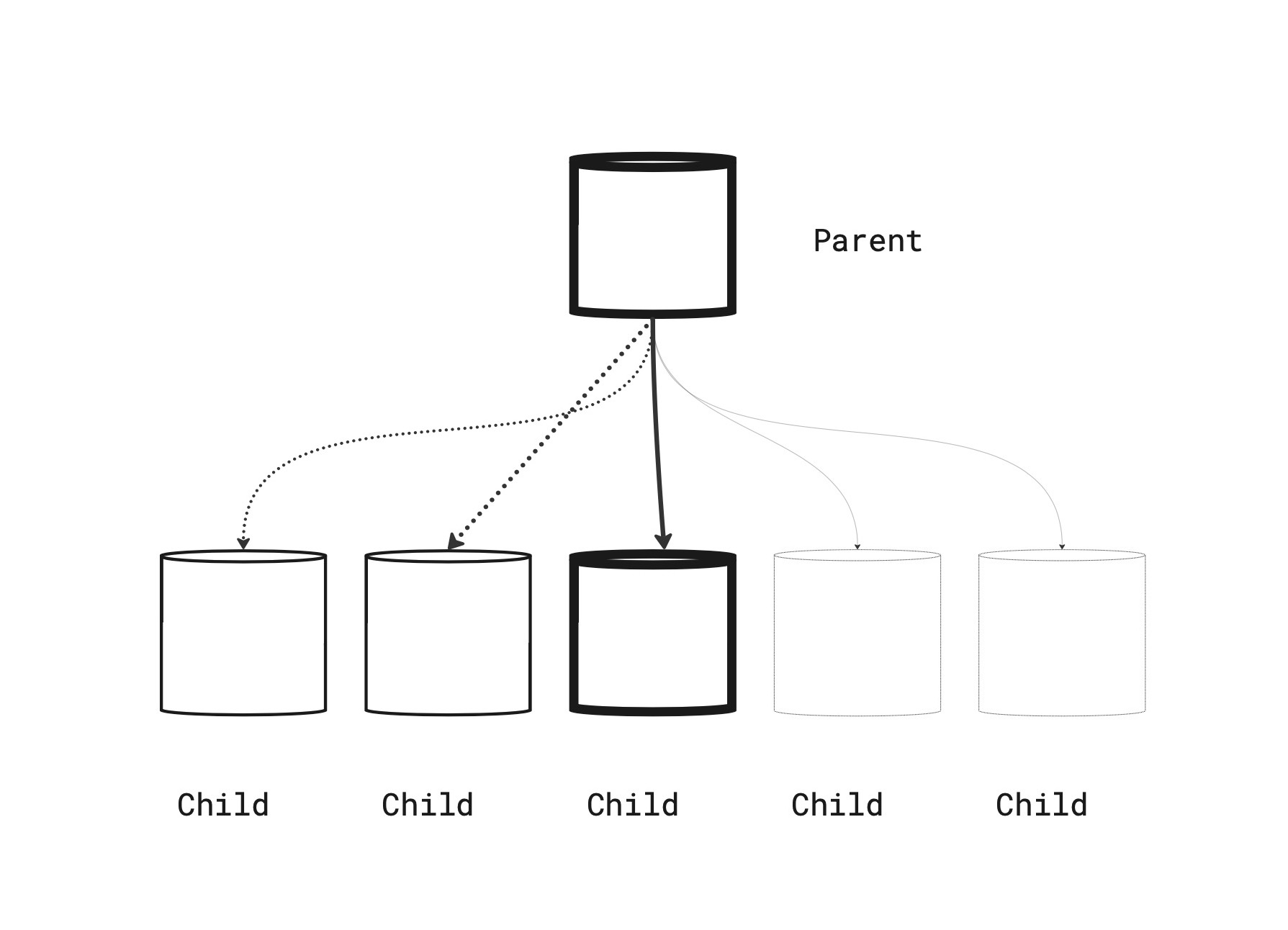
The diagram below visualizes how a partitioned table becomes a “parent” that has children tables. In our case, there is a child table per month of data.
There is one partition being actively written to, which is shown as bolded below. PostgreSQL routes INSERT statements to the current month based on the partition boundaries. Partitions for future months exist in advance, shown as a dashed line, but do not yet have any data rows.
Now that we know a little about why, the next question was how we would perform the conversion.
How
Our main database runs on PostgreSQL 13. Each release of PostgreSQL since version 10 has added improvements to Declarative Partitioning.
We use Logical Replication as part of our data pipeline process to copy row modifications into the data warehouse.
Support for Logical Replication of partitioned tables was added in version 13 1 which was good timing for our needs. Let’s look at more details of this database table.
- From the Declarative Partitioning types, we selected the
RANGEtype - We partitioned on the
created_atcolumn - We partitioned by month, which meant we needed 24 of them to cover 2 years, and then some more future months.
- We used the pgslice command line program to perform the conversion.
The conversion process was performed online, meaning there was no planned downtime.
Conversion with pgslice
pgslice is a command line program written in Ruby. The quick version of how it works is as follows.
- You make a clone of your original table, which will serve as a destination for copied rows.
- pgslice provides a batched row copying command. Using this command, you copy rows from the original table to the destination.
- Once copying has completed, update table statistics (
ANALYZE) and rename the tables
The app is now writing and reading to a partitioned table.
New inserts will flow into the current month. An important caveat of pgslice is that it’s designed for Append Only tables, meaning rows are inserted and not updated or deleted. Fortunately this table was a “mostly append only” table, and we were able to bring forward the small amount of updates using a separate process.
We manage 10 production databases each with their own copy of this table. pgslice can now be a standard tool used for our next table conversion. It’s parameterized and flexible, however we also added a small Ruby helper class to deal with some inconsistencies between databases. This helper class also serves as documentation for the arguments that each command received when they were invoked.
Row copying as a conversion technique includes significant trade-offs to be aware of. Significant testing of application code compatibility is needed with this approach. We made the app fully compatible with both types of tables simultaneously so that we could roll forward or backward.
During the conversion, more disk IO, space consumption, and WAL writes will occur. You may need to throttle down the copy process, which means it will take longer but will allow background processes like index maintenance and replication to catch up.
We recommend over provisioning your database resources and running during a low activity period. You will want lots of space capacity to run this in order to avoid disrupting application queries.
Alright, so that covers some details about our setup. How did the conversion process go?
How did it go?
The table partition conversion was successful. We’ve been running a partitioned table in all environments for several weeks now.
We did have some hiccups and addressed those issues as they arose. In Part 2 of this series,2 we’ll dig into how we solved a gnarly problem related to Primary Keys.
In collaboration with Fountain product stakeholders, a decision was made to limit the amount of data needed from this table for the application. This decision was helpful for the engineering team because it meant old data could be archived. Archiving data greatly helps the performance and reliability for this table because it may not effectively grow at a slower rate.
This also meant we could effectively shrink the total size of the table immediately.
Does this mean that some cost savings were also possible?
Cost Savings
With AWS PostgreSQL databases, relocating data out of Aurora PostgreSQL and in to object storage directly lowers costs. Aurora charges in 10 GB increments per month.3 Charges go up as you consume more space, but also down4 as you consume less space.
With this project, data may be relocated from the database to AWS S3. S3 stores the same GB-month at 80% less cost compared with Aurora, meaning there is a cost savings opportunity here.
When performing this relocation for terabytes of data, the cost savings can become meaningful. Besides the one-time cost savings, automating this relocation process means that costs will be more flat over time as opposed to perpetually increasing.
Now that we’ve covered cost savings, let’s look at what could go better next time.
Challenges and Mistakes
We work hard to avoid data loss and minimize errors. Some scenarios are impractical to fully replicate in lower environments though due to time and engineering constraints.
- Copying rows uses a lot of resources. Use batches, throttling, or stop the process if copying harms the application queries.
- Copying consumes a lot of space. Costs will increase in the short term. Make sure to export and dump retired tables so that you end up with lower costs, and not greater costs!
- Copying causes a lot of transaction log modifications. Make sure there is space capacity for consumers of the transaction log.
- Removing indexes on the destination table helped speed up the writes. Grab the create index DDL from the original table using the query below. Create the indexes again on the destination table after the rows are copied.
This query lists how the indexes were created.
SELECT indexdef FROM pg_indexes WHERE indexname = 'index_name';
Wrap Up
We hope you enjoyed this look into how we used the PostgreSQL Declarative Partitioning capability to help us solve some operational challenges for a high growth table, and how we performed an online partitioned table conversion.
If these kinds of engineering challenges interest you, please take a look at the Fountain Careers page and get in touch. Thanks for reading!
-
Partitioned tables can now be replicated https://amitlan.com/2020/05/14/partition-logical-replication.html ↩
-
PostgreSQL Table Partitioning Primary Keys — The Reckoning — Part 2 of 2 https://fountain.engineering/2023/05/04/postgresql-partitioning-primary-key/ ↩
-
CloudZero RDS Price Guide https://www.cloudzero.com/blog/rds-pricing ↩
-
Aurora Dynamic Resizing https://aws.amazon.com/about-aws/whats-new/2020/10/amazon-aurora-enables-dynamic-resizing-database-storage-space/ ↩